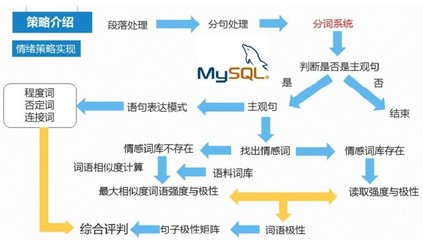
功能描述:1。新词自动识别可以自动识别词典中不存在的词,对词典的依赖性较小;2.词性输出分词包含丰富的词性;3.动态词性输出分词结果中的词性不是固定的,会根据不同的语境赋予不同的词性;4.识别特殊词汇,如化学和制药行业词汇、地名、品牌、媒体名称等。5.智能歧义消解根据内部规则,智能解决常见的分词歧义问题;6.多码识别自动识别各种单码,支持混码;7.数量词优化,自动识别量词;性能介绍:处理器:AMDAthlonIIx22503GHZ单线程大于833KB/s,多线程安全。

为了让分词更简单,用下图:Paoding(一个熟练的工人分词)是一个基于Java 中文 分词,提供lucene和solr接口的开源组件,效率很高。引入隐喻,采用完全面向对象设计,概念超前。效率高:在PIII1G内存的个人电脑上,一秒钟可以精确/123,456,789-2/100万个汉字。无限数量的字典文件用于有效地分割文章,以便可以对单词进行分类和定义。
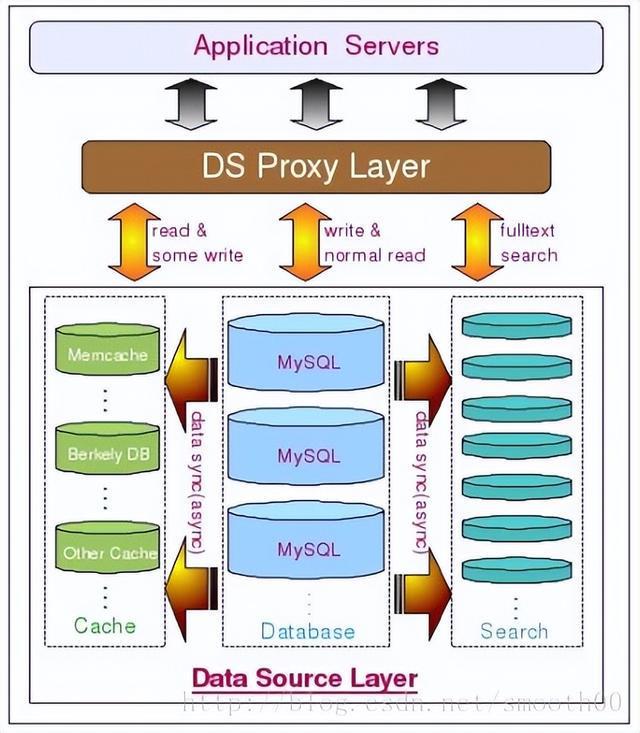
多个关键词先分后合:like% weight% sort%。我是写web的,希望在数据库上做全文检索。但是谷歌了解到中文 分词只支持英文全文搜索。为了支持中文,它需要各种插件或实现。经过仔细考虑,因为我需要的函数比较简单,主要是两个字段的搜索,而且数据量不大,即使增加几个字段,如果需要运行更多的select也不会对速度有太大影响,所以通过一些变通方法实现了需求。
这个简单的alter table ` tmp ` add full text(` column _ 1 ,` column _ 2 ...);/* * * Add * *//查询select * from ` tmp ` where match(` column _ 1 ,` column _ 2`) against ($ key )。您应该为name和description字段建立一个联合全文索引,而不是分别建立。
不支持8、 mysql能不能对 中文 分词检索
transaction,并且没有行级锁。当数据库崩溃时,锁无法安全地恢复,当读取一个表的数据时,会给该表添加一个共享锁,当写入时会添加一个独占锁。当查询表的数据时,可以同时插入一个新的记录索引特性,以支持TextBlog类型的字段作为索引,它是基于前500个字符创建的,它还支持全文索引键的延迟更新。每次修改键索引数据时,不会立即写入硬盘,而是写入内存中的键缓冲区,当缓冲区被清空或表被关闭时,会写入磁盘,但是,当数据库崩溃时,索引将会丢失,需要执行修复操作。MyISAM在创建表时对表进行压缩,表不需要修改就可以压缩,既节省了磁盘空间,又减少了磁盘I/O,从而提高了查询性能,压缩表也支持索引。







